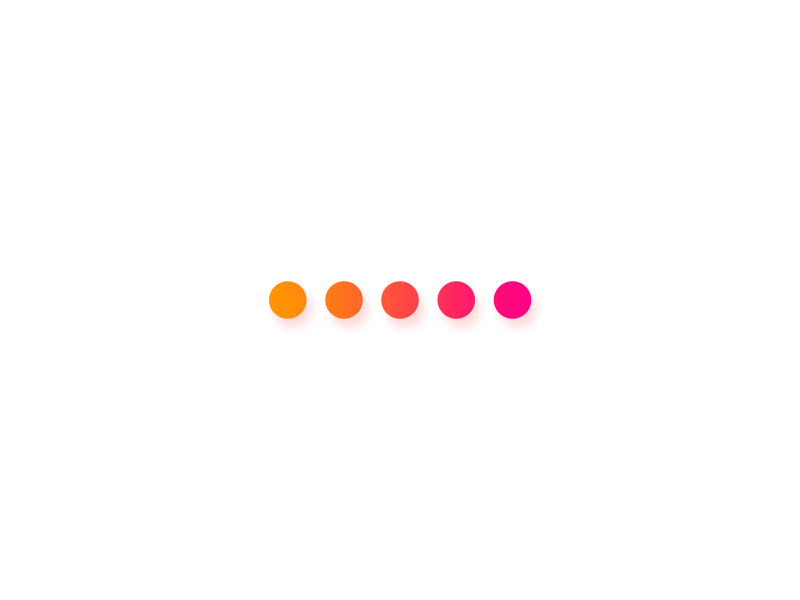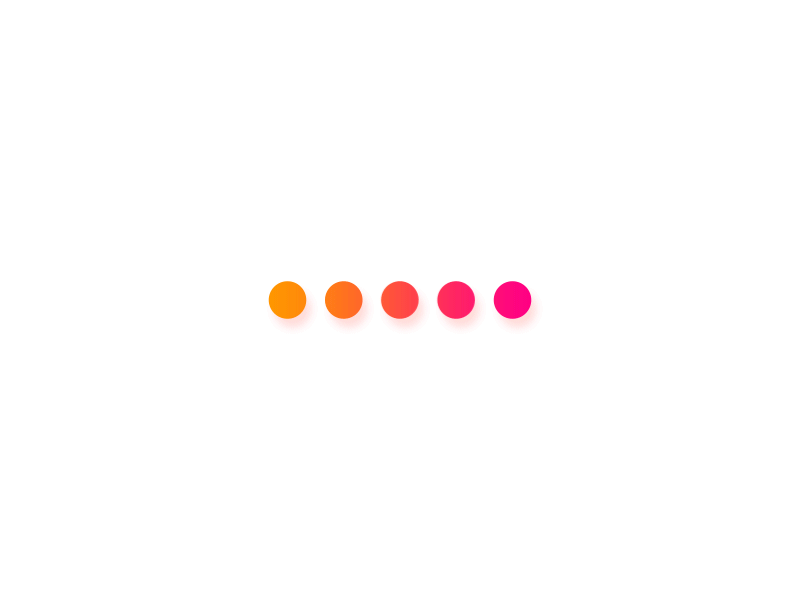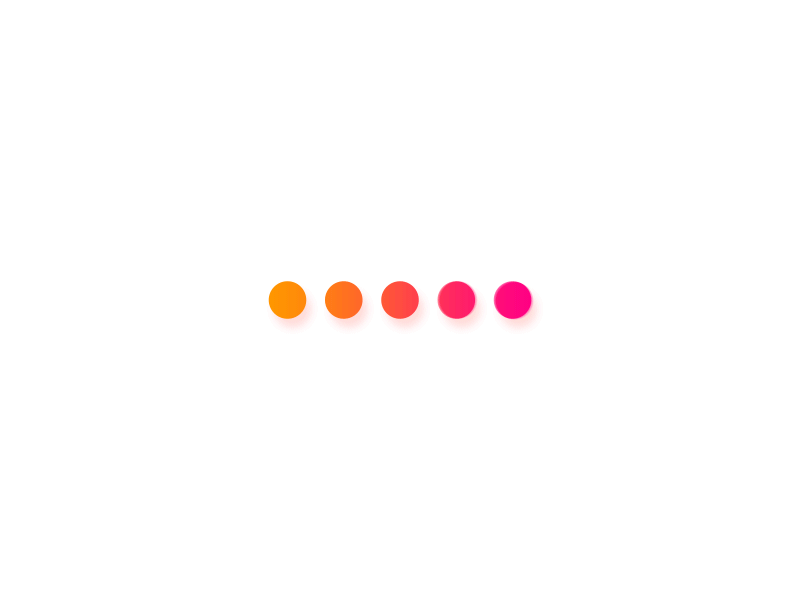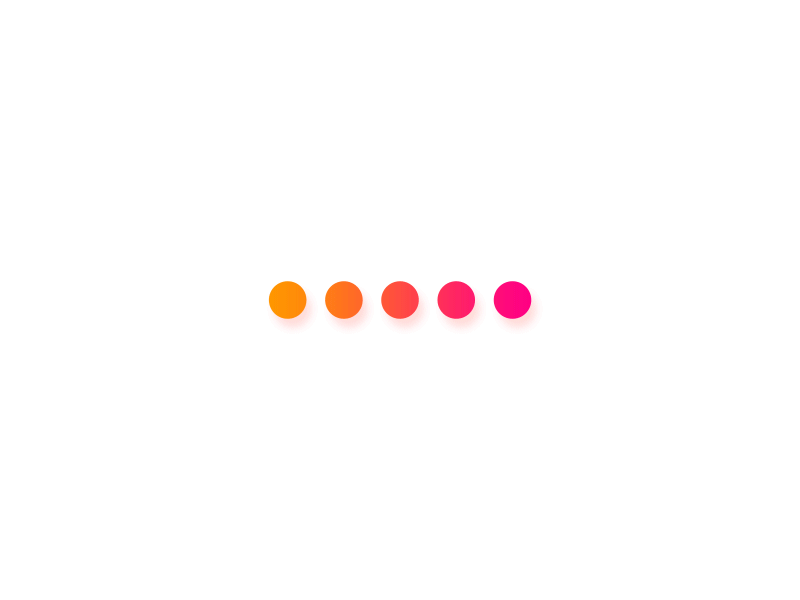线程状态
线程状态说明
初始化(Init):该线程正在被创建。
就绪(Ready):该线程在就绪列表中,等待 CPU 调度。
运行(Running):该线程正在运行。
阻塞(Blocked):该线程被阻塞挂起。Blocked 状态包括:pend(锁、 事件、信号量等阻塞)、suspend(主动 pend)、delay(延时阻塞)、 pendtime(因为锁、事件、信号量时间等超时等待)
退出(Exit):该线程运行结束,等待父线程回收其控制块资源
竞争条件和临界区
竞争条件(Race Condition)是指当两个或多个线程访问共享数据时,对数据的访问顺序取决于线程调度的顺序,而导致程序出现错误结果的情况。
临界区(Critical Section)是指一段程序中访问共享资源(如全局变量、共享内存等)的代码片段,每次只允许一个线程访问,如果多个线程同时访问,就会导致竞争条件。
为了避免竞争条件和保护临界区,需要使用同步机制,例如互斥锁、条件变量、信号量等,来协调线程之间的访问,保证共享资源在任何时刻都只被一个线程访问。
互斥锁
互斥锁mutex
互斥锁(Mutex)是多线程编程中最常用的同步机制之一,主要用于保护共享资源,防止多个线程同时访问同一份数据。当一个线程获得了互斥锁之后,其他线程就不能再获取该互斥锁,只能等待该线程释放该互斥锁后才能获取它。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
#incldue <iostream>
#include <thread>
#include <mutex>
using namespace std;
static mutex mux;
void TestThread()
{
mux.lock();
cout << "===============================" << endl;
cout << "test 001" << endl;
cout << "test 002" << endl;
cout << "test 003" << endl;
cout << "===============================\n" << endl;
mux.unlock();
}
int main(int argc, char* argv[])
{
for (int i = 0; i < 10; i++)
{
thread th(TestThread);
th.detach();
}
getchar();
return 0;
}
|
互斥锁的问题
在使用互斥锁时,需要注意避免死锁(Deadlock)的问题,即多个线程相互等待对方释放锁而陷入无限等待的状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
mutex mux;
void ThreadMainMux(int i)
{
//不断的循环可能会导致某个线程独占锁
for (;;)
{
mux.lock();
cout << i << "[in]" << endl;
this_thread::sleep_for(1000ms);
mux.unlock();
//通过让刚获取过锁的线程睡眠一会,防止独占
this_thread::sleep_for(1ms);
}
}
int main(int argc,char *argv[])
{
for (int i = 0; i < 3; i++)
{
thread th(ThreadMainMux, i+1);
th.detach();
}
//....
}
|
超时锁time_mutex—避免长时间死锁
time_mutex(超时锁)是一种基于互斥锁的扩展,它允许在给定的超时时间内获取互斥锁。它在多线程编程中非常有用,因为它可以防止线程在获取互斥锁时无限期地阻塞,从而导致死锁。在获取互斥锁时,线程会等待一段时间,如果在超时时间内没有获得锁,则线程会放弃获取锁。
一般情况下,互斥锁是一种阻塞锁,如果一个线程获取不到锁,则会一直等待,直到另一个线程释放了锁。而使用超时锁,可以避免线程阻塞时间过长,造成线程资源的浪费,从而提高程序的性能。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
timed_mutex tmux;
void ThreadMainTime(int i)
{
for (;;)
{
if (!tmux.try_lock_for(milliseconds(1000)))
{
cout << i << "[try_lock_for] timeout" << endl;
continue;
}
cout << i << "[in]" << endl;
this_thread::sleep_for(2000ms);
tmux.unlock();
this_thread::sleep_for(1ms);
}
}
int main(int argc,char *argv[])
{
for (int i = 0; i < 3; i++)
{
thread th(ThreadMainTime, i);
th.detach();
}
// ...
}
|
递归锁 recursive_mutex 和 recursive_timed_mutex
recursive_mutex 和 recursive_timed_mutex 都是互斥锁的类型,它们的特点是可以被同一线程多次获得,即支持递归锁。具体来说,一个线程可以多次获得一个递归锁,但是在这个线程释放同样次数的锁之前,其它线程无法获得这个锁。
recursive_mutex 和 recursive_timed_mutex 的区别在于前者没有超时限制,而后者支持超时限制。在使用时,可以通过成员函数 lock()、try_lock() 和 unlock() 来进行锁的操作。
递归锁的使用场景通常是在函数或类成员函数的递归调用中,避免出现死锁等问题。例如,在递归地遍历一棵树的时候,可能需要在每个节点上获取锁,避免并发修改节点数据导致数据不一致或者崩溃的问题。此时,如果使用普通的互斥锁,会因为同一线程多次获取锁而造成死锁,而使用递归锁则能够很好地解决这个问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
recursive_mutex rmux;
void Task1()
{
rmux.lock();
// 组合业务 用到同一个锁
cout << "task1 [in]" << endl;
rmux.unlock();
}
void Task2()
{
rmux.lock();
// 组合业务 用到同一个锁
cout << "task2 [in]" << endl;
rmux.unlock();
}
void ThreadMainRec(int i)
{
for (;;)
{
rmux.lock();
// 组合业务 用到同一个锁
Task1();
Task2();
cout << i << "[in]" << endl;
this_thread::sleep_for(2000ms);
rmux.unlock();
this_thread::sleep_for(1ms);
}
}
int main(int argc,char *argv[])
{
for (int i = 0; i < 3; i++)
{
thread th(ThreadMainRec, i);
th.detach();
}
//....
}
|
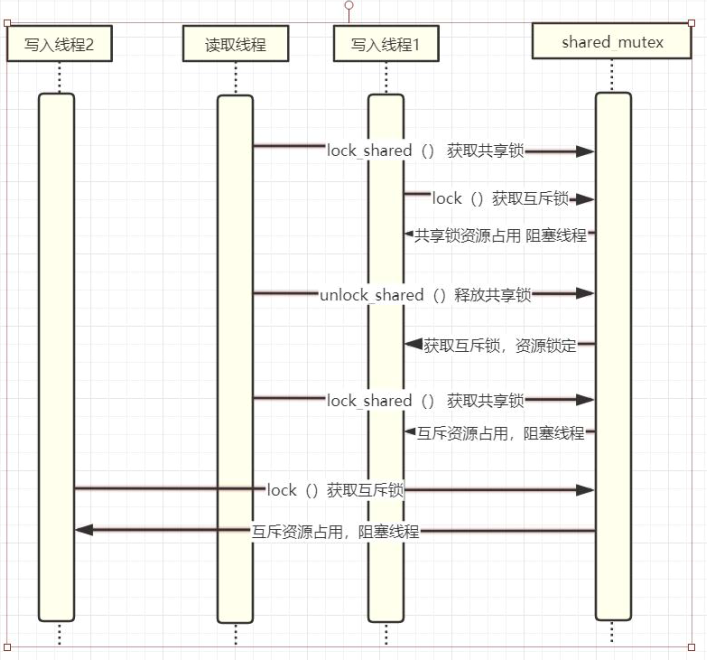
共享锁share_mutex
std::shared_mutex 是一个提供共享访问控制的互斥量。与 std::mutex 不同,它允许多个线程同时访问共享资源,提高了并发性能。
std::shared_mutex 支持两种锁定方式:独占锁和共享锁。当一个线程拥有独占锁时,它可以独占地访问被保护的资源。当多个线程拥有共享锁时,它们可以同时读取被保护的资源。与 std::mutex 不同的是,多个线程可以同时拥有共享锁,而只有一个线程可以拥有独占锁。
使用 std::shared_mutex 时,可以调用 std::shared_mutex::lock() 函数获得独占锁,并调用 std::shared_mutex::lock_shared() 函数获得共享锁。与独占锁不同,共享锁不会阻塞其他线程获取共享锁,但会阻塞其他线程获取独占锁。在完成对被保护资源的读取后,必须调用 std::shared_mutex::unlock_shared() 或 std::shared_mutex::unlock() 函数释放锁。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
//c++17
shared_mutex smux;
//c++ 14
shared_timed_mutex stmux;
void ThreadWrite(int i)
{
for (;;)
{
stmux.lock_shared();
//读数据
stmux.unlock_shared();
stmux.lock();
cout << i << " Write" << endl;
this_thread::sleep_for(100ms);
stmux.unlock();
this_thread::sleep_for(3000ms);
}
}
void ThreadRead(int i)
{
for(;;)
{
stmux.lock_shared();
cout << i << " Read" << endl;
this_thread::sleep_for(500ms);
stmux.unlock_shared();
this_thread::sleep_for(50ms);
}
}
int main(int argc,char *argv[])
{
for (int i = 0; i < 3; i++)
{
thread th(ThreadWrite, i + 1);
th.detach();
}
this_thread::sleep_for(100ms);
for (int i = 0; i < 3; i++)
{
thread th(ThreadRead, i + 1);
th.detach();
}
//...
}
|
利用栈特性自动释放锁 RAII
在多线程编程中,经常需要用到锁来保证共享资源的同步访问。一般情况下,在获取锁之后需要在适当的时候手动释放锁,否则就会出现死锁等问题。而RAII技术可以自动管理锁的生命周期,确保在使用完锁之后能够自动释放锁。
使用RAII技术实现自动释放锁的方法是定义一个类,在类的构造函数中获取锁,在类的析构函数中释放锁。这样,只要定义的类实例在作用域内,就可以保证获取到锁,并在离开作用域时自动释放锁。
什么是RAII,手动代码实现
RAII(Resource Acquisition Is Initialization)是一种C++编程技术,旨在管理资源的生命周期,确保资源在需要时被正确地获取,并在使用后被正确地释放。利用栈特性自动释放锁就是RAII技术在多线程编程中的应用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
class XMutex
{
public:
XMutex(mutex& mux):mux_(mux)
{
cout << "Lock" << endl;
mux_.lock();
}
~XMutex()
{
cout << "UnLock" << endl;
mux_.unlock();
}
private:
mutex &mux_;
}
|
支持的RAII管理互斥资源 lock_guard
std::lock_guard 的构造函数需要一个互斥锁对象作为参数,当它的作用域被创建时,会调用互斥锁的 lock() 方法锁住资源,当作用域结束时,析构函数自动释放锁,从而保证了锁在有需要的时候上锁,在不需要的时候释放锁。
在调用方已经拥有互斥锁的所有权时,可以使用std::adopt_lock_t参数来表示锁已经被持有,避免在std::lock_guard的析构函数中再次进行加锁操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
//lock_guard 源代码
template <class _Mutex>
class lock_guard {
// class with destructor that unlocks a mutex
public:
using mutex_type = _Mutex;
explicit lock_guard(_Mutex& _Mtx) : _MyMutex(_Mtx) {
// construct and lock
_MyMutex.lock();
}
lock_guard(_Mutex& _Mtx, adopt_lock_t) : _MyMutex(_Mtx) {
// construct but don't lock
}
~lock_guard() noexcept {
_MyMutex.unlock();
}
lock_guard(const lock_guard&) = delete;
lock_guard& operator=(const lock_guard&) = delete;
};
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
#include <thread>
#include <iostream>
#include <string>
#include <mutex>
#include <shared_mutex>
//Linux -lpthread
using namespace std;
static mutex gmutex;
void TestLockGuard(int i)
{
gmutex.lock();
{
//已经拥有锁,不lock
lock_guard<mutex> lock(gmutex,adopt_lock);
//结束释放锁
}
{
lock_guard<mutex> lock(gmutex);
cout << "begin thread " << i << endl;
}
for (;;)
{
{
lock_guard<mutex> lock(gmutex);
cout << "In " << i << endl;
}
this_thread::sleep_for(500ms);
}
}
int main(int argc, char* argv[])
{
for (int i = 0; i < 3; i++)
{
thread th(TestLockGuard, i + 1);
th.detach();
}
getchar();
return 0;
}
|
unique_lock
它提供了比 lock_guard 更多的灵活性。unique_lock 的特点是支持锁的所有权的转移、可被中断的锁等待、延后拥有、以及超时的锁等待。
使用 unique_lock 时,可以通过构造函数或成员函数指定互斥量,并且可以指定锁的状态:已锁或未锁。若指定了已锁状态,则会立即尝试对互斥量加锁;若指定未锁状态,则可以在需要时手动加锁。在 unique_lock 对象生命周期结束时,会自动解锁互斥量。
defer_lock
std::unique_lock 对象的延后拥有(deferred ownership)是指在创建 unique_lock 对象时并不立即锁定互斥量,而是在对象的某个后续时刻进行锁定。这种锁定方式有时可以提高代码的效率。
延后拥有可以通过在创建 std::unique_lock 对象时,将第二个参数设为 std::defer_lock 来实现。这会使 unique_lock 对象不会立即尝试获取互斥量的所有权。之后,可以调用 unique_lock 对象的 lock 成员函数来获取互斥量的所有权
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
//延后拥有
#include <mutex>
#include <thread>
#include <iostream>
std::mutex mtx;
void func()
{
std::unique_lock<std::mutex> lck(mtx, std::defer_lock);
// ... some other operations
lck.lock(); // 程序执行到此处时才会锁定互斥量
// ... critical section
}
int main()
{
std::thread t1(func);
std::thread t2(func);
t1.join();
t2.join();
return 0;
}
|
try_to_lock
std::unique_lock 中的 try_to_lock 选项表示尝试锁定互斥量但不会阻塞线程,而是立即返回。如果互斥量当前被另一个线程锁定,则 try_to_lock 操作将不会等待该线程释放互斥量,而是返回一个指示锁定失败的值。如果互斥量当前未被锁定,则尝试锁定它并返回一个指示锁定成功的值。此操作不会阻塞线程,因此可以用于非阻塞代码中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#include <iostream>
#include <thread>
#include <mutex>
int main() {
std::mutex mtx;
std::unique_lock<std::mutex> lck(mtx, std::try_to_lock);
if (lck.owns_lock()) {
std::cout << "Mutex locked by this thread" << std::endl;
}
else {
std::cout << "Mutex not available" << std::endl;
}
return 0;
}
|
在此示例中,std::unique_lock 尝试锁定 std::mutex,但不会阻塞线程。如果锁定成功,则输出 Mutex locked by this thread。否则,输出 Mutex not available。
shared_lock(c++14)
shared_lock是一个在共享情况下保护共享数据的锁,允许多个线程同时访问共享数据。与unique_lock不同,shared_lock支持共享锁定和延迟锁定。
shared_lock是由<shared_mutex>头文件中的std::shared_lock类实现的。它可以与std::shared_mutex或std::shared_timed_mutex一起使用,以实现共享所有权的锁。[[03 多线程通信与同步#5、共享锁share_mutex|share_mutex]]
与unique_lock一样,shared_lock也使用RAII技术来管理锁的生命周期。在构造函数中获取锁,在析构函数中释放锁。可以通过lock()和unlock()方法手动控制锁的获取和释放。
与unique_lock不同的是,shared_lock提供了lock_shared()方法来获取共享锁,它会阻塞线程直到可以获得共享锁。try_lock_shared()方法则尝试获取共享锁,如果无法获取则立即返回,不会阻塞线程。此外,shared_lock还提供了unlock_shared()方法来释放共享锁。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
#include <iostream>
#include <thread>
#include <shared_mutex>
std::shared_mutex mutex;
int shared_data = 0;
void read_thread() {
std::shared_lock<std::shared_mutex> lock(mutex);
std::cout << "Reading shared_data: " << shared_data << std::endl;
}
void write_thread() {
//组合使用,也可以和lock_guard组合使用
std::unique_lock<std::shared_mutex> lock(mutex);
shared_data++;
std::cout << "Writing shared_data: " << shared_data << std::endl;
}
int main() {
std::thread t1(read_thread);
std::thread t2(read_thread);
std::thread t3(write_thread);
t1.join();
t2.join();
t3.join();
return 0;
}
|
shared_lock 是一个共享的互斥锁,用于读取共享资源。相比 unique_lock 和 lock_guard,它的特点是可以被多个线程同时获取锁并访问共享资源,因此能够提高并发性能。
但是,shared_lock 也存在一些缺陷,例如不能在获取锁后修改共享资源(因为它是一个共享锁),不能使用 try_lock() 函数尝试获取锁等。
因此,将 shared_lock 与 unique_lock、lock_guard 结合使用,可以在获取锁时根据具体情况选择使用 shared_lock 或 unique_lock/lock_guard,从而兼顾并发性能和对共享资源的修改操作。比如,在读多写少的场景中,可以使用 shared_lock 获取读取锁,而在需要修改共享资源时,再使用 unique_lock 获取写入锁。这种方式称为“读写分离”,可以有效地提高并发性能。
scoped_lock(c++17)
scoped_lock 是一个 C++11 中的锁类型,它是一个锁卫士(lock guard)类型,可以用来保护多个锁的同时加锁和解锁。scoped_lock 在构造函数中获得指定的锁,并在析构函数中释放所有已获取的锁。因此,它遵循 RAII 原则,可以防止忘记释放锁,避免死锁的问题。
scoped_lock 类的构造函数可以接受多个互斥量,并按照定义的顺序对这些互斥量进行加锁。同时,scoped_lock 还支持不同的锁类型,比如 std::mutex、std::timed_mutex、std::recursive_mutex 等等。如果在构造函数中无法获取所有互斥量的锁,则会阻塞当前线程,直到获取所有互斥量的锁为止。
c++11
std::lock 是一个函数模板,用于在一个操作中锁定多个互斥量,以避免死锁。它会锁定提供的互斥量,如果所有互斥量都成功锁定,则函数返回。如果某个互斥量无法锁定,则所有已经锁定的互斥量都将被解锁,以避免死锁。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
#include <iostream>
#include <mutex>
#include <thread>
int counter = 0;
std::mutex m1, m2;
void increment_both()
{
std::scoped_lock lock(m1, m2);
++counter;
}
int main()
{
std::thread t1(increment_both);
std::thread t2(increment_both);
t1.join();
t2.join();
std::cout << "Counter value: " << counter << std::endl;
return 0;
}
|
总结
条件变量
条件变量(condition variable)是一种线程间同步的机制,它允许一个线程等待另一个线程满足某个特定条件。当条件不满足时,线程可以进入等待状态,不会消耗 CPU 资源,直到另一个线程满足了条件并通知等待线程。
在 C++ 中,条件变量通常和互斥量(mutex)一起使用,来实现线程之间的同步。具体来说,当一个线程在条件变量上等待时,它会释放对互斥量的占有,让其他线程能够访问共享资源。等待线程会在条件变量被通知时,重新获取互斥量的占有,检查条件是否已满足,如果满足,则继续执行;如果不满足,则继续等待。
C++ 中使用条件变量需要借助 std::condition_variable 类,它定义在 <condition_variable> 头文件中。常见的使用方式是定义一个条件变量对象和一个互斥量对象,然后在等待线程中使用条件变量对象的 wait() 函数来等待条件的满足,使用 notify_one() 或 notify_all() 函数来通知等待线程条件已经满足。
condition_variable
在调用 wait() 函数时,需要提供一个已经加锁的互斥量对象作为参数,即 std::unique_lock<std::mutex>,这个互斥量是用来保护条件变量的。
当线程调用 wait() 后,它会释放互斥量的所有权,然后等待条件变量被通知。当条件变量被其他线程通知后,线程会重新获得互斥量的所有权并从 wait() 函数返回,此时它可以再次使用共享资源。
需要注意的是,虽然 wait() 在等待期间会释放锁,但当它被唤醒后会自动重新获取锁,所以唤醒线程应该在释放锁之前完成所有必要的修改。
生产者-消费者模型
- 生产者和消费者共享资源变量(list队列)
- 生产者生产一个产品,通知消费者消费
- 消费者阻塞等待信号-获取信号后消费产品(取出list队列中数据)
(一)改变共享变量的线程步骤(生产者线程)
1
|
std::condition_variable cv;
|
- 获得 std::mutex (常通过 std::unique_lock )
1
2
3
|
lock.unlock();
cv.notify_one(); //通知一个等待信号线程
cv.notify_all(); //通知所有等待信号线程
|
(二)等待信号读取共享变量的线程步骤
1
2
3
4
5
6
|
//解锁lock,并阻塞等待 notify_one notify_all 通知
cv.wait(lock);
//接收到通知会再次获取锁标注,也就是说如果此时mux资源被占用,wait函数会阻塞
msgs_.front();
//处理数据
msgs_.pop_front();
|
- 2 lambada 表 达 式
cv.wait(lock, [] {return !msgs_.empty();});
只在 std::unique_lockstd::mutex 上工作的 std::condition_variable
1
2
3
4
5
6
7
8
9
10
11
12
13
|
void wait(unique_lock<mutex>& _Lck) {
// wait for signal
// Nothing to do to comply with LWG‐2135 because std::mutex lock/unlock are nothrow
_Check_C_return(_Cnd_wait(_Mycnd(), _Lck.mutex()->_Mymtx()));
}
template <class _Predicate>
void wait(unique_lock<mutex>& _Lck, _Predicate _Pred) {
// wait for signal and test predicate
while (!_Pred())
{
wait(_Lck);
}
}
|
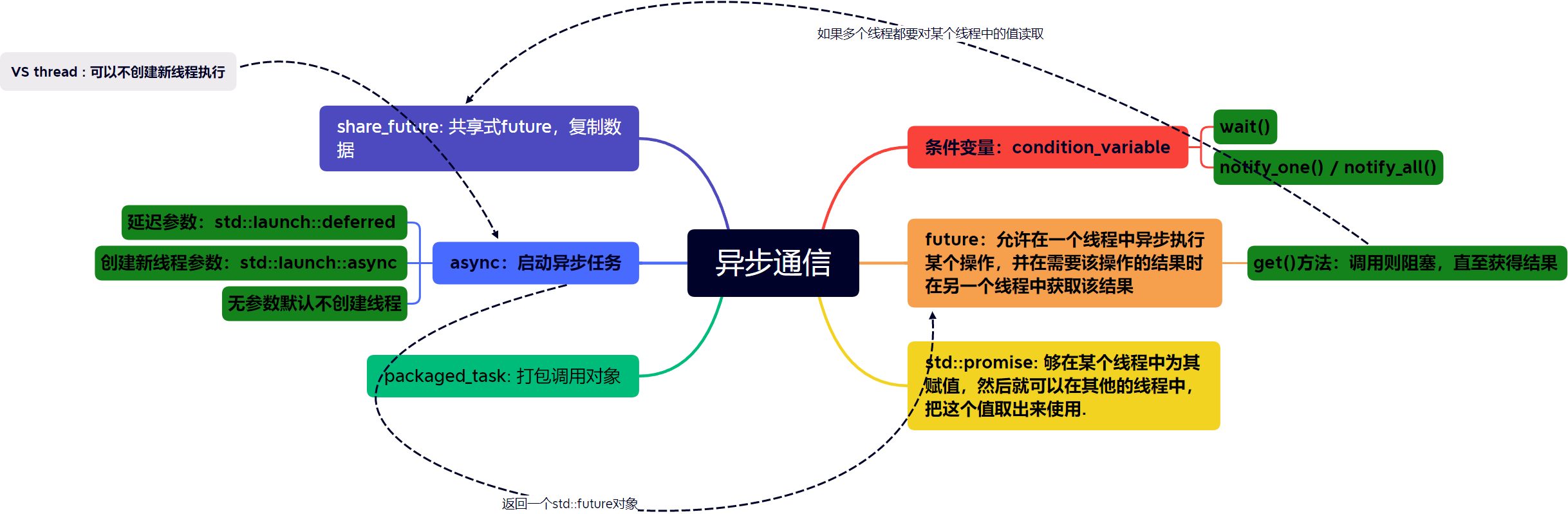
线程异步和通信
条件变量和互斥锁 VS promise 和 future
条件变量和互斥锁是一种解决并发同步的方案,而 promise 和 future 则是另外一种解决方案。它们的异同点如下:
- 异同点:
- 条件变量和互斥锁通常用于解决多个线程对共享数据的并发访问问题,通过互斥锁实现数据的独占和同步,而条件变量则用于在多线程之间进行通信,等待某个条件满足时唤醒线程。promise 和 future 则主要用于解决单个线程内的异步操作问题。
- promise 和 future 通过一个线程设置某个值,并在另一个线程中获取该值,实现异步操作和同步等待。在实现异步操作时,线程不必等待某个操作完成,而是可以继续执行其他操作,然后在需要该操作结果时,通过 future 来获取该结果。这种方式避免了线程的阻塞等待,提高了并发性能。
- 进步:
- promise 和 future 支持异步操作,使得线程可以并发执行多个操作,提高了并发性能,而条件变量和互斥锁则只能在单个线程内进行同步等待,无法实现多线程的并发执行。
- packaged_task 结合 future 和异步任务,可以实现任务的延迟执行,也就是可以把任务提交到一个线程池中,等待线程池中的线程执行。
总的来说,互斥锁和条件变量主要解决的是多线程之间的数据同步和互斥访问,而 promise 和 future 主要解决的是单个线程内的异步操作和同步等待,两者各有优劣,具体使用时需要根据具体的场景和需求来选择。而packaged_task 则结合了两者的优点,实现了异步任务的延迟执行。
promise 和 future
promise 用于异步传输变量。这是一个类模饭,这个类模板的作用是:能够在某个线程中为其赋值,然后就可以在其他的线程中,把这个值取出来使用。
std::promise 提供存储异步通信的值,再通过其对象创建的std::future异步获得结果。
std::promise 只能使用一次。 void set_value(_Ty&& _Val) 设置传递值,只能掉用一次
std::future 提供访问异步操作结果的机制
get() 阻塞等待promise set_value 的值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
void TestFuture(promise<string> p)
{
//假装有业务1
//一设置,主线成中get就结束阻塞
ps.set_value("TestFuture value");
//继续线程业务
//假装有业务2
}
int main()
{
//这段代码创建了一个 promise 对象 p,并通过 get_future() 成员函数获取了一个与该 promise 对象相关联的 future 对象。通过这个 future 对象,我们可以在异步任务完成后获取其返回值。在这个例子中,promise 对象和 future 对象之间建立了一条双向通道,通过该通道,异步任务产生的结果可以传递给等待其完成的线程。
//使用 `move(p)` 的原因是要将 `p` 对象转移到新线程中。由于 `promise` 对象不可复制,因此将其作为参数传递给新线程需要使用 `move` 将其所有权转移到新线程中,否则编译器会报错。如果直接传递 `p`,编译器会尝试进行拷贝,但由于 `promise` 对象不可复制,编译器会报错。另外,`move(p)` 的语义是将 `p` 对象的状态转移到新的对象中,并使 `p` 对象的状态处于一个无效但可销毁的状态。因此,在将 `p` 对象转移给另一个对象之后,就不能再次使用 `p` 对象了,因为其状态已经无效。
promise<string> p;
auto fu = p.get_future(); //std::future<string>
auto re = std::thread(TestFuture,move(p));
//get方法只要线程一设置了value就立刻停止阻塞,而不需要等待线程结束
cout << "fu = " << fu.get() << endl;;
cout << "end std::async" << endl;
re.join();
return 0;
}
//始终都是一个线程在活动
|
packaged_task 异步调用函数打包
![[Recording 20230221135027.webm]]
std::packaged_task 是一个模板类,用于将一个可调用对象(函数、函数指针、函数对象)封装成一个可调用的任务(task),并且可以将任务的结果传递给一个 std::future 对象。其实现方式是将一个函数对象和一个 std::promise 对象结合起来,从而实现了在不同的线程之间传递一个可调用对象并且获取其返回值的功能。
总的来说,就是将调用和返回值分离开来!
举个例子,假设我们有一个函数 add,可以计算两个整数的和,并且希望将其封装成一个任务,在另外一个线程中执行。使用 std::packaged_task 可以这么做
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
string TestPack(int index)
{
cout << "begin Test Pack " << index << endl;
this_thread::sleep_for(2s);
return "Test Pack return";
}
int main(int argc, char* argv[])
{
packaged_task< string(int) > task(TestPack);
auto result = task.get_future();
//task(100);
//⭐我在这里调用
//使用`move`将`task`转移给新线程中的`packaged_task`对象,以确保在将任务与新线程关联之后,不会再有其他线程对该任务进行修改。如果不使用`move`,则可能会导致多个线程同时访问同一个`packaged_task`对象,从而导致不可预知的行为。
thread th(move(task),101);
cout << "begin result get" << endl;
//测试是否超时
//⭐我在这里取返回值
for (int i = 0; i < 30; i++)
{
if (result.wait_for(100ms) != future_status::ready)
{
continue;
}
}
if (result.wait_for(100ms) == future_status::timeout)
{
cout << "wait result timeout" << endl;
}
else
cout << "result get " << result.get() << endl;
th.join();
getchar();
return 0;
}
|
async 创建异步线程
C++11 异步运行一个函数,并返回保有其结果的std::future
launch::deferred 延迟执行 在调用wait和get时,调用函数代码launch::async 创建线程(默认)- 返回的线程函数的返回值类型的
std::future<int> (std::future<线程函数的返回值类型>)
- re.get() 获取结果,会阻塞等待
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
string TestAsync(int index)
{
cout << index<<" begin in TestAsync " << this_thread::get_id() << endl;
this_thread::sleep_for(2s);
return "TestAsync string return";
}
int main(int argc, char* argv[])
{
//创建异步线程
cout << "main thread id " << this_thread::get_id() << endl;
//不创建线程启动异步任务
//result.get来请求结果,那么这个异步任务就运行在执行这条 get 语句所在的线程上.,而不创建新线程
auto future = async(launch::deferred, TestAsync,100);
this_thread::sleep_for(100ms);
cout << "begin future get " << endl;
cout << "future.get() = " << future.get() << endl;
cout << "end future get" << endl;
//创建异步线程
cout << "=====创建异步线程====" << endl;
auto future2 = async(TestAsync, 101);
this_thread::sleep_for(100ms);
cout << "begin future2 get " << endl;
cout << "future2.get() = " << future2.get() << endl;
cout << "end future2 get" << endl;
getchar();
return 0;
}
|
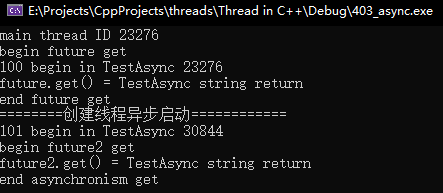
所谓的不创建线程,就是主线程自行运行
总结