⚠默认基于Nasm汇编器和x86架构下的汇编 , 仅MASM支持会特殊标注
一、数值编码
-
无符号整数(Unsigned Integer):
- 使用二进制补码(Binary Unsigned Integer)表示。
- 所有位都可用于表示数值,没有符号位。
- 最高位为数值的最高位,没有特殊含义。
- 能表示的范围:0 到 (2^n - 1),其中 n 是该整数类型的位数。
-
有符号整数(Signed Integer):
- 使用二进制补码(Binary Two’s Complement)表示。
- 最高位(最左侧的位)作为符号位,0 表示正数,1 表示负数。
- 其余位表示数值部分,使用正数的二进制补码表示。
- 能表示的范围:-(2^(n-1)) 到 (2^(n-1) - 1),其中 n 是该整数类型的位数。
-
小数(Floating-point Number):
- 使用浮点表示法,例如IEEE 754标准。
- 一般分为单精度(32位)和双精度(64位)两种格式。
- 包括符号位、指数位和尾数位,用于表示带有小数部分的实数。
- 能表示的范围和精度取决于具体的浮点表示格式。
-
字符(Character):
- 使用字符编码表来表示,最常见的是ASCII编码或Unicode编码。
- 通常每个字符占用一个固定大小的字节(如ASCII编码中的一个字节),或者使用多字节表示(如某些Unicode编码)。
- 每个编码表将字符映射到一个二进制值,以便在计算机中表示。
-
字符串(String):
- 字符串是由多个字符构成的序列。
- 在计算机中,字符串通常被表示为字符数组或字符指针,其中每个字符使用字符的表示方式进行存储。
- 字符串的具体表示方式可以根据编程语言和字符串库的不同而有所区别,但基本原理是相同的。
需要注意的是,每种数据类型在计算机中的具体表示方式可能会因编程语言、编译器、操作系统或硬件平台而有所差异。这些表示方式是通过约定和标准来定义的,以确保数据在计算机内部的正确解释和操作。
二、变量
1、MASM中的变量
1.1 定义变量
变量名即汇编语句名字部分,是用户自定义的标识符,表示初值表首个数据的逻辑地址。汇编语言使用这个符号表示地址,故有时被称为符号地址。变量名可以没有,这种情况,汇编程序将直接为初值表分配空间,无符号地址。设置变量名是为了方便存取它指示的存储单元。
|
|
1.1.1 初值表
初值表是用逗号分隔的参数,由各种形式的常量和特殊的符号“?”、“DUP”组成。其中“?”表示初值不确定,即未赋初值。多个存储单元如果初值相同,可以用复制操作符DUP进行说明。
|
|
1.1.2 变量定义伪指令
变量定义伪指令有DB、DW、DD、DF、DQ和DT(NASM和MASM使用了相同的伪指令 , MASM 6.0开始还对应支持BYTE、WORD、DWORD、FWORD、QWORD和TBYTE,两者功能相同),它们根据申请的主存空间单位分类

除了 DB、DW、DD 等定义的简单变量,汇编语言还支持复杂的数据变量,例如结构(Structure)、记录(Record)、联合(Union)等。
1.2 变量定位
变量定义的存储空间是按照书写的先后顺序一个接一个分配的。而定位伪指令可以控制其存放的偏移地址。
1.2.1 ORG伪指令
ORG伪指令将参数表达的偏移地址作为当前偏移地址,格式是:
|
|
例如,从偏移地址100H处安排数据或程序,可以使用语句:
|
|
1.2.2 ALIGN与Even伪指令
在汇编语言中,“Align"和"Even"是两个常用的伪指令,它们的作用是调整代码或数据的对齐方式。
-
Align(对齐)伪指令:
- Align伪指令用于将代码或数据对齐到指定的边界。
- 对齐是指将数据或指令的起始地址设置为特定的边界地址,通常是内存地址的倍数。
- 对齐可以提高程序执行效率和访问速度,尤其在一些体系结构中,要求某些特定类型的数据必须以特定的对齐方式存储。
- 使用Align伪指令,程序员可以指定对齐的边界,如字节、字(2字节)、双字(4字节)等。
-
Even(偶数)伪指令:
- Even伪指令用于将代码或数据的起始地址对齐到偶数地址。
- 在某些体系结构中,要求32位数据的起始地址必须为偶数,即内存地址的最低位必须为0。
- 使用Even伪指令,程序员可以确保代码或数据的起始地址为偶数地址,从而满足特定体系结构的要求。
这些对齐伪指令可以在编写汇编代码时使用,以确保数据的正确对齐和访问。对齐方式的选择通常受到特定体系结构或编译器的要求和限制。通过使用Align和Even伪指令,程序员可以以最佳的方式进行数据对齐,以提高代码执行效率和访问速度。
1.2.3 变量属性
变量定义除分配存储空间和赋初值外,还可以创建变量名。 这个变量名一经定义便具有两类属性: (1)地址属性——指首个变量所在存储单元的逻辑地址,含有段基地址和偏移地址。 (2)类型属性——指变量定义的数据单位,有字节量、字量、双字量、3 字量、4 字量和10字节量,依次用类型名BYTE、WORD、DWORD、FWORD、QWORD和TBYTE表示。
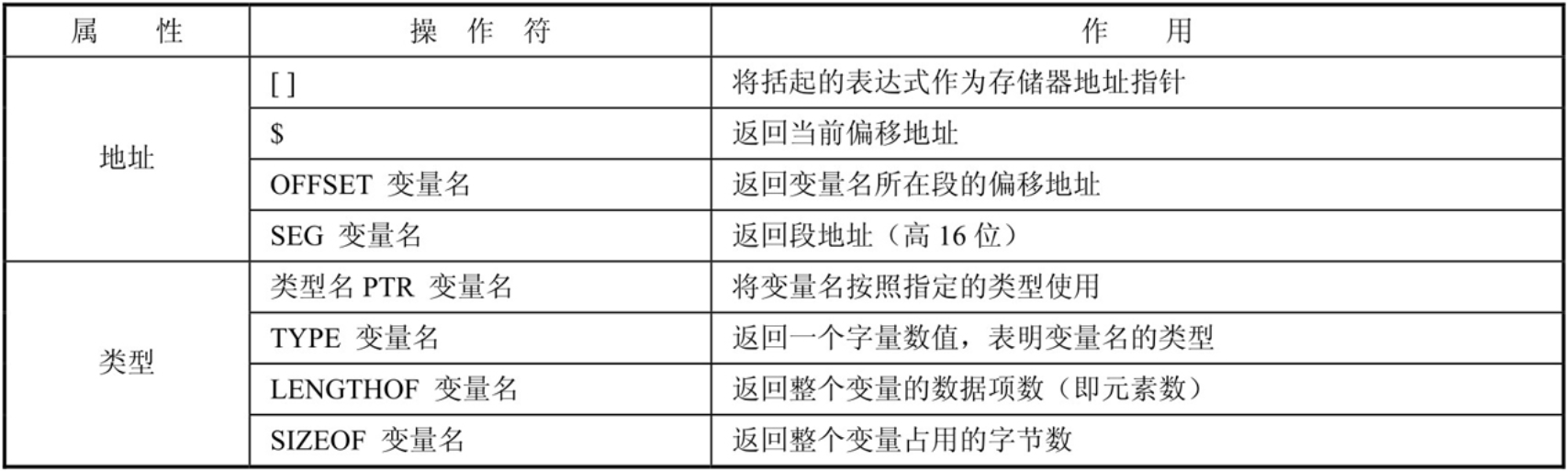
TYPE返回该类型变量一个数据项所占的字节数,例如对字节、字和双字变量依次返回1、2和4 对变量,还可以用LENGTHOF操作符获知某变量名指向多少个数据项,用SIZEOF操作符获知它共占用多少字节空间,即 SIZEOF 值=TYPE 值×LENGHOF 值
|
|
2、NASM中的变量
在NASM中,可以使用%define、equ和resb等指令来创建变量。
- 使用
%define定义符号常量:
|
|
这种方式创建的变量是一个符号常量,它们在汇编时会被替换为具体的值。例如:
|
|
这样就定义了一个名为 SIZE 的变量,它的值为 10。在后续的代码中,可以直接使用 SIZE 来代表 10。
- 使用
equ定义符号常量:
|
|
这种方式与 %define 类似,也是用于定义符号常量。例如:
|
|
这样就定义了一个名为 SIZE 的变量,它的值为 10。在后续的代码中,同样可以直接使用 SIZE 来代表 10。
- 使用
resb分配内存空间:
变量名 resb 长度
这种方式用于在内存中分配一定长度的字节空间,即创建一个字节长度的变量。例如:
|
|
这样就创建了一个名为 array 的变量,它占用了 10 个字节的空间。
除了 resb,NASM还提供了其他类似的分配内存空间的指令,如 resw(分配字)和 resd(分配双字)。可以根据具体需要选择适当的指令。
三、寻址方式
1、立即寻址
|
|
2、寄存器寻址
指令执行时,操作的数位于寄存器中,可以从寄存器里取得
|
|
3、内存寻址
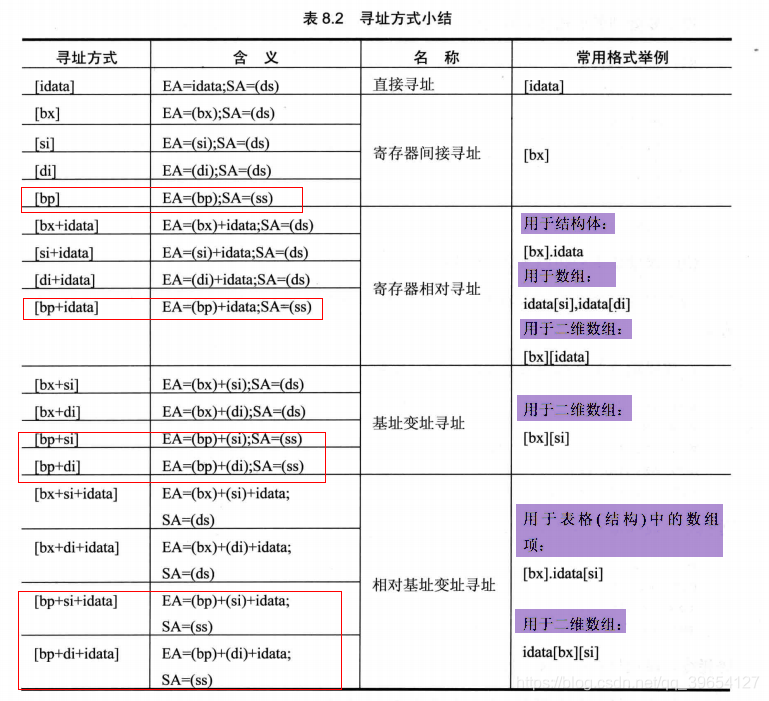
所谓的内存寻址,就是如何在指令中指定操作数的偏移地址,供处理器访问内存时使用,这个偏移地址就叫做有效地址(EA,Effective Address)
3.1 直接寻址
|
|
3.2 基址寻址
所谓基址寻址,就是先指定一个基准位置,数据的偏移数据(有效地址)取决于它到基准位置的位移或者说距离,要使用基地寻址,需要在指定的地址部分使用基址寄存器BX或者BP来提供一个基准地址(默认情况下, BX默认寄存器DS, BP默认寄存器SS) , 可以在BX和BP的基础上加上位移
|
|
一个小例子
|
|
3.3 变址寻址
变址寻址类似于基址寻址,唯一不同之处在于这种寻址方式使用的是变址寄存器(或称索引寄存器)SI和DI , 除非使用了段超越前缀,默认使用DS作为段寄存器,同样可以增加位移
|
|
3.4 基址变址寻址
可以使用一个基址寄存器(BX或者BP) + 变址寄存器(SI和DI) = 基址变址
|
|
一个例子
|
|
[1] 《汇编语言》王爽
[2] 《x86汇编语言:从实模式到保护模式(第二版)》李忠、王晓波、余洁
[3] 《Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3A: System Programming Guide, Part 1》
[4] 《汇编语言简明教程》钱晓捷
[6] 《NASM中文手册》
[7] 《MASM61 Pro Guide》


