重要说明,这篇博文是一位大神的微信公众号:bin的技术小屋 中的一篇推文的阅读笔记,因为写的太好了,基本上就是摘抄,已经将文章的链接放在参考文献中,仅仅作为本人的阅读笔记使用,感谢大神的分享精神,共勉。
对齐填充问题
逻辑核心与物理核心
一个CPU里面包含多个核心,我们在购买电脑的时候经常会看到这样的处理器配置,比如4核8线程。意思是这个CPU包含4个物理核心8个逻辑核心。4个物理核心表示在同一时间可以允许4个线程并行执行,8个逻辑核心表示处理器利用超线程的技术将一个物理核心模拟出了两个逻辑核心,一个物理核心在同一时间只会执行一个线程,而超线程芯片可以做到线程之间快速切换,当一个线程在访问内存的空隙,超线程芯片可以马上切换去执行另外一个线程。因为切换速度非常快,所以在效果上看到是8个线程在同时执行。
CPU缓存行
CPU高速缓存中存取数据的基本单位叫做缓存行cache line。缓存行存取字节的大小为2的倍数,在不同的机器上,缓存行的大小范围在32字节到128字节之间。目前所有主流的处理器中缓存行的大小均为64字节(注意:这里的单位是字节)。
每次CPU从内存中获取数据或者写入数据的大小为64个字节,即使你只读一个bit,CPU也会从内存中加载64字节数据进来。同样的道理,CPU从高速缓存中同步数据到内存也是按照64字节的单位来进行。 比如你访问一个long型数组,当CPU去加载数组中第一个元素时也会同时将后边的7个元素一起加载进缓存中。这样一来就加快了遍历数组的效率
事实上,你可以非常快速的遍历在连续的内存块中分配的任意数据结构,如果你的数据结构中的项在内存中不是彼此相邻的(比如:链表),这样就无法利用CPU缓存的优势。由于数据在内存中不是连续存放的,所以在这些数据结构中的每一个项都可能会出现缓存行未命中(程序局部性原理)的情况
False Sharing (伪共享)
volatile 关键字
我们知道声明了volatile关键字的变量可以在多线程处理环境下,确保内存的可见性。计算机硬件层会保证对被volatile关键字修饰的共享变量进行写操作后的内存可见性,而这种内存可见性是由Lock前缀指令以及缓存一致性协议(MESI控制协议)共同保证的。
Lock前缀指令可以使修改线程所在的处理器中的相应缓存行数据被修改后立马刷新回内存中,并同时锁定所有处理器核心中缓存了该修改变量的缓存行,防止多个处理器核心并发修改同一缓存行。
缓存一致性协议主要是用来维护多个处理器核心之间的CPU缓存一致性以及与内存数据的一致性。每个处理器会在总线上嗅探其他处理器准备写入的内存地址,如果这个内存地址在自己的处理器中被缓存的话,就会将自己处理器中对应的缓存行置为无效,下次需要读取的该缓存行中的数据的时候,就需要访问内存获取。
一个程序分析伪共享的产生
|
|
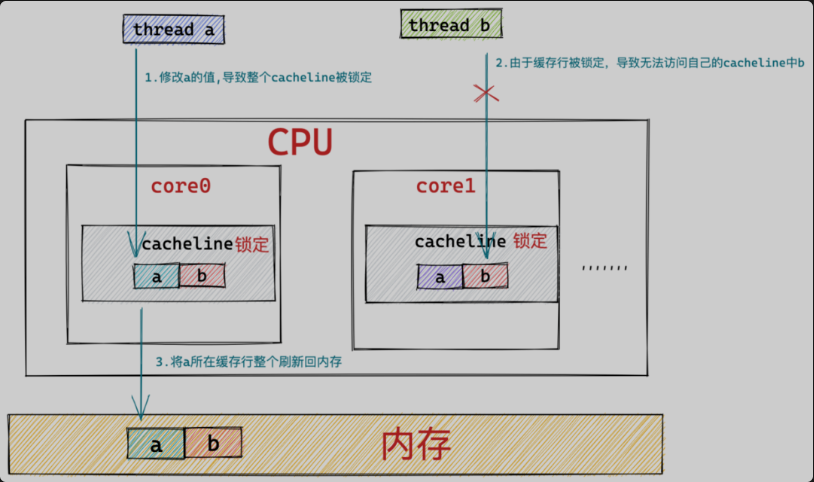
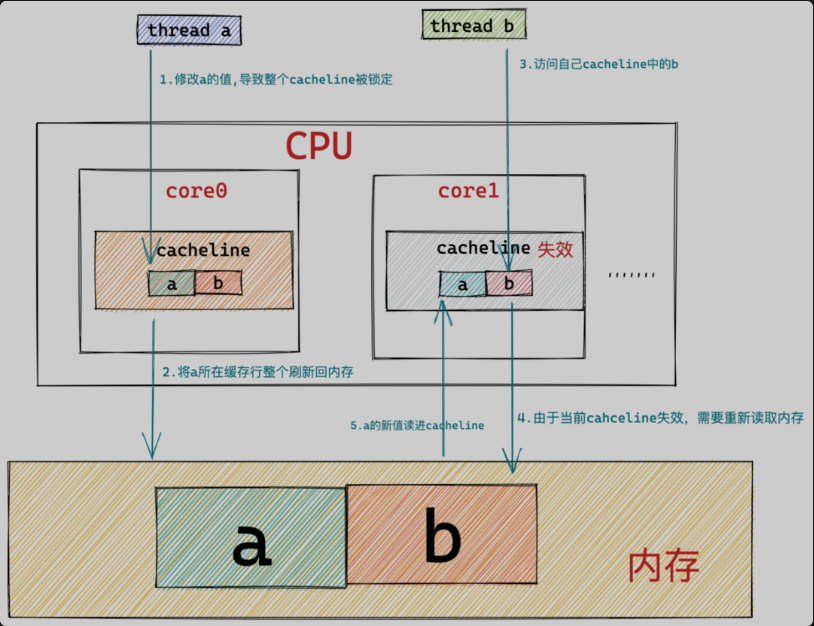
从以上两种影响我们看到字段a与字段b实际上并不存在共享,它们之间也没有相互关联关系,理论上线程a对字段a的任何操作,都不应该影响线程b对字段b的读取或者写入。 但事实上线程a对字段a的修改导致了字段b在core1中的缓存行被锁定(Lock前缀指令),进而使得线程b无法读取字段b。 线程a所在处理器core0将字段a所在缓存行同步刷新回内存后,导致字段b在core1中的缓存行被置为失效(缓存一致性协议),进而导致线程b需要重新回到内存读取字段b的值无法利用CPU缓存的优势。 由于字段a和字段b在同一个缓存行中,导致了字段a和字段b事实上的共享(原本是不应该被共享的)。这种现象就叫做False Sharing(伪共享)。 在高并发的场景下,这种伪共享的问题,会对程序性能造成非常大的影响。 如果线程a对字段a进行修改,与此同时线程b对字段b也进行修改,这种情况对性能的影响更大,因为这会导致core0和core1中相应的缓存行相互失效。
伪共享的解决方案
字节填充,将一个变量填充到和缓存行大小一致
CPU Adjacent Sector Prefetch是Intel处理器特有的BIOS功能特性,默认是enabled。主要作用就是利用程序局部性原理,当CPU从内存中请求数据,并读取当前请求数据所在缓存行时,会进一步预取与当前缓存行相邻的下一个缓存行,这样当我们的程序在顺序处理数据时,会提高CPU处理效率。这一点也体现了程序局部性原理中的空间局部性特征。
内存对齐
DRAM的访问过程
存储控制器会将内存地址转换为DRAM芯片中supercell在二维矩阵中的坐标地址(RAS,CAS)。并将这个坐标地址发送给对应的存储器模块。随后存储器模块会将RAS和CAS广播到存储器模块中的所有DRAM芯片。依次通过(RAS,CAS)从DRAM0到DRAM7读取到相应的supercell。
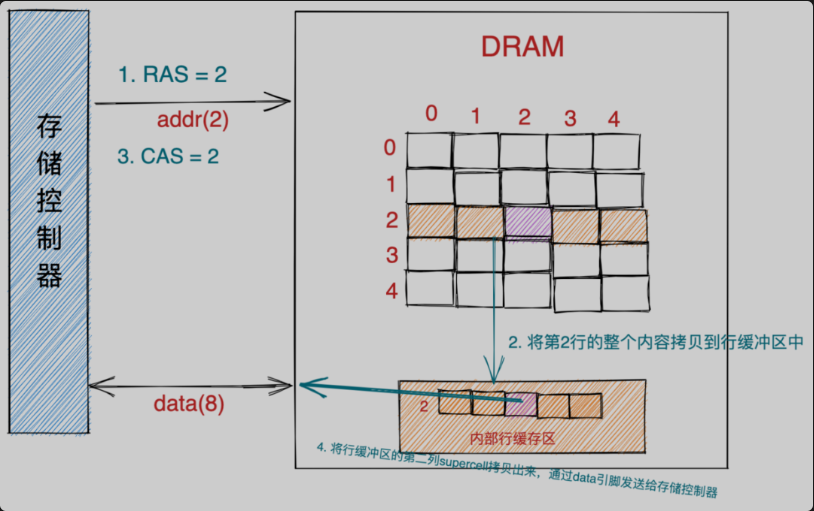
- 首先存储控制器将行地址
RAS = 2通过地址引脚发送给DRAM芯片。 - DRAM芯片根据
RAS = 2将二维矩阵中的第二行的全部内容拷贝到内部行缓冲区中。 - 接下来存储控制器会通过地址引脚发送
CAS = 2到DRAM芯片中。 - DRAM芯片从内部行缓冲区中根据
CAS = 2拷贝出第二列的supercell并通过数据引脚发送给存储控制器。 我们知道一个supercell存储了8 bit数据,这里我们从DRAM0到DRAM7 依次读取到了8个supercell也就是8个字节,然后将这8个字节返回给存储控制器,由存储控制器将数据放到存储总线上。
CPU读内存
假设CPU现在要将内存地址为A的内容加载到寄存器中进行运算。
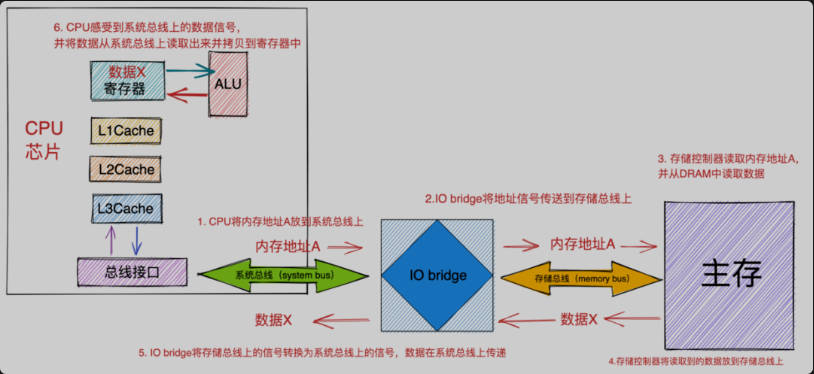
- CPU将内存地址A放到系统总线上。随后
IO bridge将信号传递到存储总线上。 - 主存感受到存储总线上的
地址信号并通过存储控制器将存储总线上的内存地址A读取出来。 - 存储控制器通过内存地址A定位到具体的存储器模块,从
DRAM芯片中取出内存地址A对应的数据X。 - 存储控制器将读取到的
数据X放到存储总线上,随后IO bridge将存储总线上的数据信号转换为系统总线上的数据信号,然后继续沿着系统总线传递。 - CPU芯片感受到系统总线上的数据信号,将数据从系统总线上读取出来并拷贝到寄存器中。
总线结构CPU与内存之间的数据交互是通过总线(bus)完成的,而数据在总线上的传送是通过一系列的步骤完成的,这些步骤称为总线事务(bus transaction)。 其中数据从内存传送到CPU称之为
读事务(read transaction),数据从CPU传送到内存称之为写事务(write transaction)。 总线上传输的信号包括:地址信号,数据信号,控制信号。其中控制总线上传输的控制信号可以同步事务,并能够标识出当前正在被执行的事务信息:
- 当前这个事务是到内存的?还是到磁盘的?或者是到其他IO设备的?
- 这个事务是读还是写?
- 总线上传输的地址信号(
内存地址),还是数据信号(数据)?。 还记得我们前边讲到的MESI缓存一致性协议吗?当core0修改字段a的值时,其他CPU核心会在总线上嗅探字段a的内存地址,如果嗅探到总线上出现字段a的内存地址,说明有人在修改字段a,这样其他CPU核心就会失效自己缓存字段a所在的cache line。 如上图所示,其中系统总线是连接CPU与IO bridge的,存储总线是来连接IO bridge和主存的。IO bridge负责将系统总线上的电子信号转换成存储总线上的电子信号。IO bridge也会将系统总线和存储总线连接到IO总线(磁盘等IO设备)上。这里我们看到IO bridge其实起的作用就是转换不同总线上的电子信号。
CPU写内存
- CPU将要写入的内存地址A放入系统总线上。
- 通过
IO bridge的信号转换,将内存地址A传递到存储总线上。 - 存储控制器感受到存储总线上的地址信号,将内存地址A从存储总线上读取出来,并等待数据的到达。
- CPU将寄存器中的数据拷贝到系统总线上,通过
IO bridge的信号转换,将数据传递到存储总线上。 - 存储控制器感受到存储总线上的数据信号,将数据从存储总线上读取出来。
- 存储控制器通过内存地址A定位到具体的存储器模块,最后将数据写入存储器模块中的8个DRAM芯片中。
为什么要内存对齐
速度
CPU读取数据的单位是根据word size来的,在64位处理器中word size = 8字节,所以CPU向内存读写数据的单位为8字节。
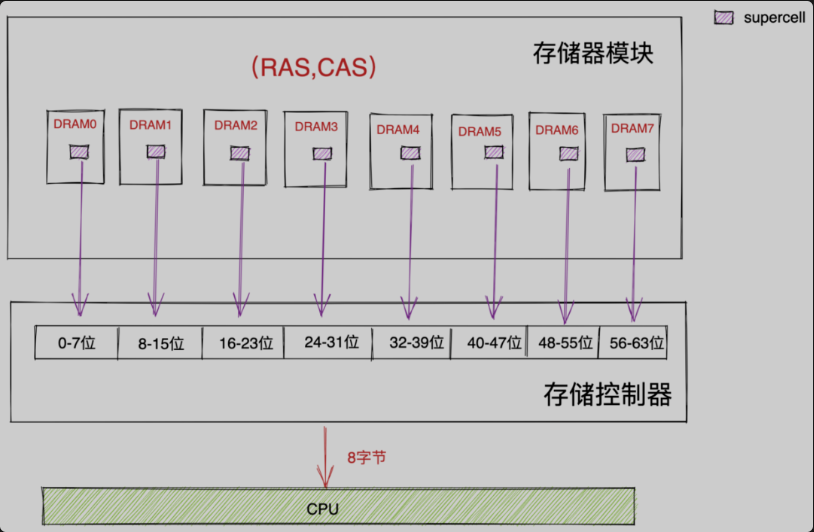
在64位内存中,内存IO单位为8个字节,我们前边也提到内存结构中的存储器模块通常以64位为单位(8个字节)传输数据到存储控制器上或者从存储控制器传出数据。因为每次内存IO读取数据都是从数据所在具体的存储器模块中包含的这8个DRAM芯片中以相同的(RAM,CAS)依次读取一个字节,然后在存储控制器中聚合成8个字节返回给CPU。
假设读取0x0000 - 0x0007
由于内存读取是按照8个字节为单位依次顺序读取的,而我们要读取的这段内存地址的起始地址是0(8的倍数),所以0x0000 - 0x0007中每个地址的坐标都是相同的(RAS,CAS)。所以他可以在8个DRAM芯片中通过相同的(RAS,CAS)一次性读取出来。
但如果我们现在读取0x0007 - 0x0014这段连续内存上的8个字节情况就不一样了
由于起始地址0x0007在DRAM芯片中的(RAS,CAS)与后边地址0x0008 - 0x0014的(RAS,CAS)不相同,所以CPU只能先从0x0000 - 0x0007读取8个字节出来先放入结果寄存器中并左移7个字节(目的是只获取0x0007),然后CPU在从0x0008 - 0x0015读取8个字节出来放入临时寄存器中并右移1个字节(目的是获取0x0008 - 0x0014)最后与结果寄存器或运算。最终得到0x0007 - 0x0014地址段上的8个字节。
两次访问内存自然在速度上就有差距了!
原子性
CPU可以原子地操作一个对齐的word size memory
缓存友好
处理器中的cache line大小为64字节,堆中对象的起始地址通过内存对齐至8的倍数,可以让对象尽可能的分配到一个缓存行中。一个内存起始地址未对齐的对象可能会跨缓存行存储,这样会导致CPU的执行效率慢2倍。


