如何衡量处理器性能
应用的执行时间等于指令数乘以CPI(Cycles Per Instruction,每指令执行周期数)再乘以时钟周期,当算法、程序、指令系统、编译器都确定之后,一个应用的指令数就确定下来了,时钟周期与结构设计、电路设计、生产工艺以及工作环境都有关系,本文注重讨论如何降低CPI,即如何通过结构设计提高流水线效率
流水线CPI=理想CPI+结构相关阻塞周期数+RAW阻塞周期数+WAR阻塞周期数+WAW阻塞周期数+控制相关阻塞周期数
多发射
最直观的方法就是让处理器中==每级流水线都可以同时处理更多的指令,这被称为多发射数据通路技术==。例如双发射流水线意味着每一拍用PC从指令存储器中取两条指令,在译码级同时进行两条指令的译码、读源寄存器操作,还能同时执行两条指令的运算操作和访存操作,并同时写回两条指令的结果。那么双发射流水线的理想CPI就从单发射流水线的1降至0.5。 要在处理器中支持多发射,==首先就要将处理器中的各种资源翻倍==,包括采用支持双端口的存储器。其次还要增加额外的阻塞判断逻辑,当同一个时钟周期执行的两条指令存在指令相关时,也需要进行阻塞。包括数据相关、控制相关和结构相关在内的阻塞机制都需要改动。
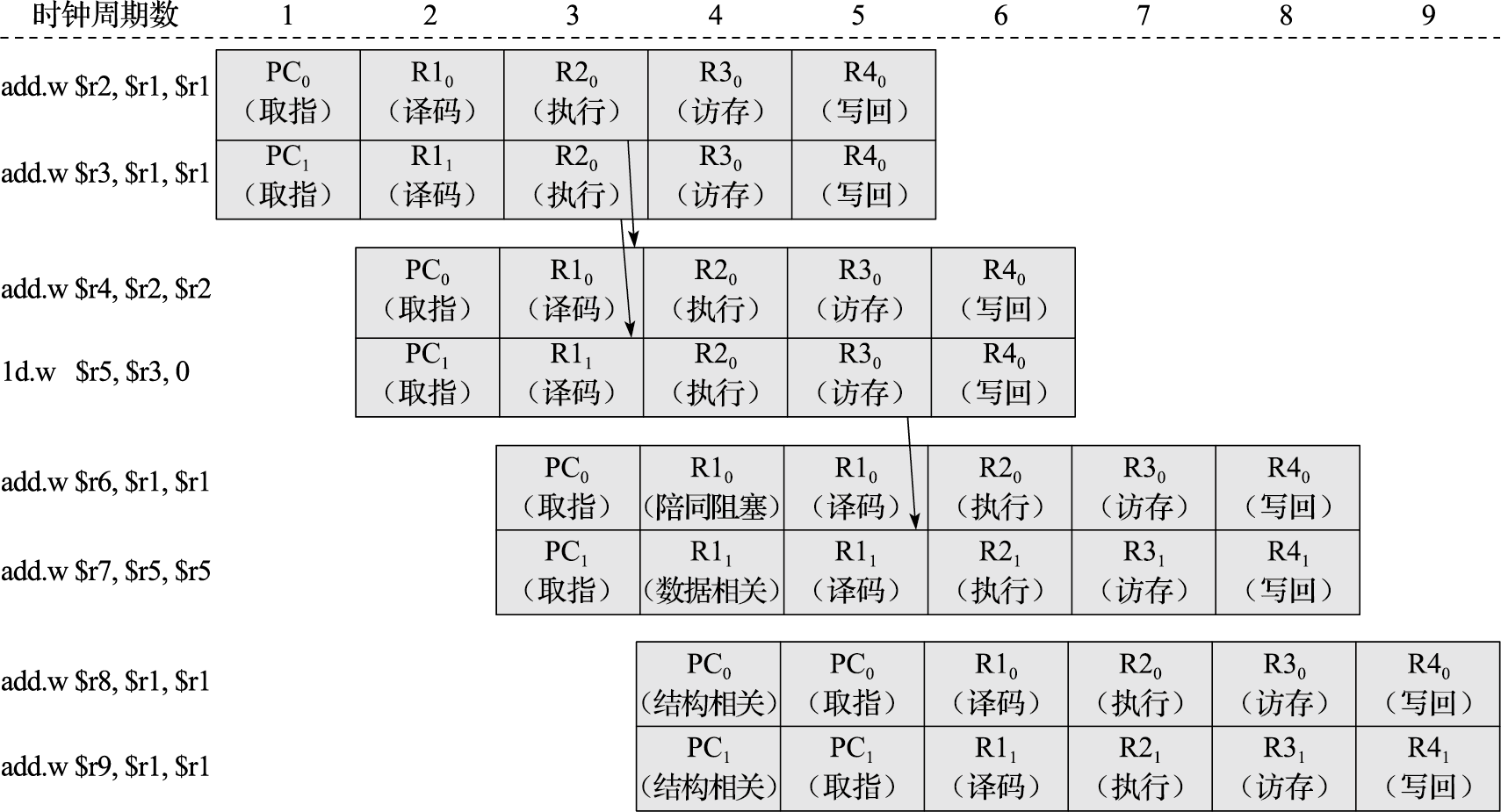
多发射数据通路技术虽然从理论上而言可以大幅度降低处理器的CPI,但是由于各类相关所引起的阻塞影响,其实际执行效率是要大打折扣的。所以我们还要进一步从减少各类相关引起的阻塞这个方面入手来提高流水线的执行效率。
动态调度
如果我们用道路交通来类比的话,多发射数据通路就类似于把马路从单车道改造为多车道,但是这个多车道的马路有个奇怪的景象——速度快的车(如跑车)不能超过前面速度慢的车(如马车),即使马车前面的车道是空闲的。直觉上我们肯定觉得这样做效率低,只要车道有空闲,就应该允许后面速度快的车超过前面速度慢的车。这就是动态调度的基本出发点
动态调度器通过分析指令之间的依赖关系和资源的可用性,选择最合适的指令进行执行。它可以重新排序指令的执行顺序,以最大程度地减少指令之间的相关性和等待时间。这种指令重排序可以利用程序中的并行性,提高指令级并行和数据流并行的执行效率。
通过动态调度,CPU可以更好地隐藏指令延迟和资源竞争的影响,提高指令的吞吐量和整体性能。动态调度器还可以对指令进行一些优化,比如重命名寄存器、执行细分等,以进一步提高执行效率。
转移预测
现代处理器普遍采用==硬件转移预测机制==来解决转移指令引起的控制相关阻塞,==其基本思路是在转移指令的取指或译码阶段预测出转移指令的方向和目标地址,并从预测的目标地址继续取指令执行,这样在猜对的情况下就不用阻塞流水线==。
既然是猜测,就有错误的可能。硬件转移预测的实现分为两个步骤:第一步是预测,即在取指或译码阶段预测转移指令是否跳转以及转移的目标地址,并根据预测结果进行后续指令的取指;第二步是确认,即在转移指令执行完毕后,比较最终确定的转移条件和转移目标与之前预测的结果是否相同,如果不同则需要取消预测后的指令执行,并从正确的目标重新取指执行。
高速缓存
Cache是微体系结构的概念,它没有程序上的意义,没有独立的编址空间,处理器访问Cache和访问存储器使用的是相同的地址,因而Cache对于编程功能正确性而言是透明的
Cache设计需要考虑的问题
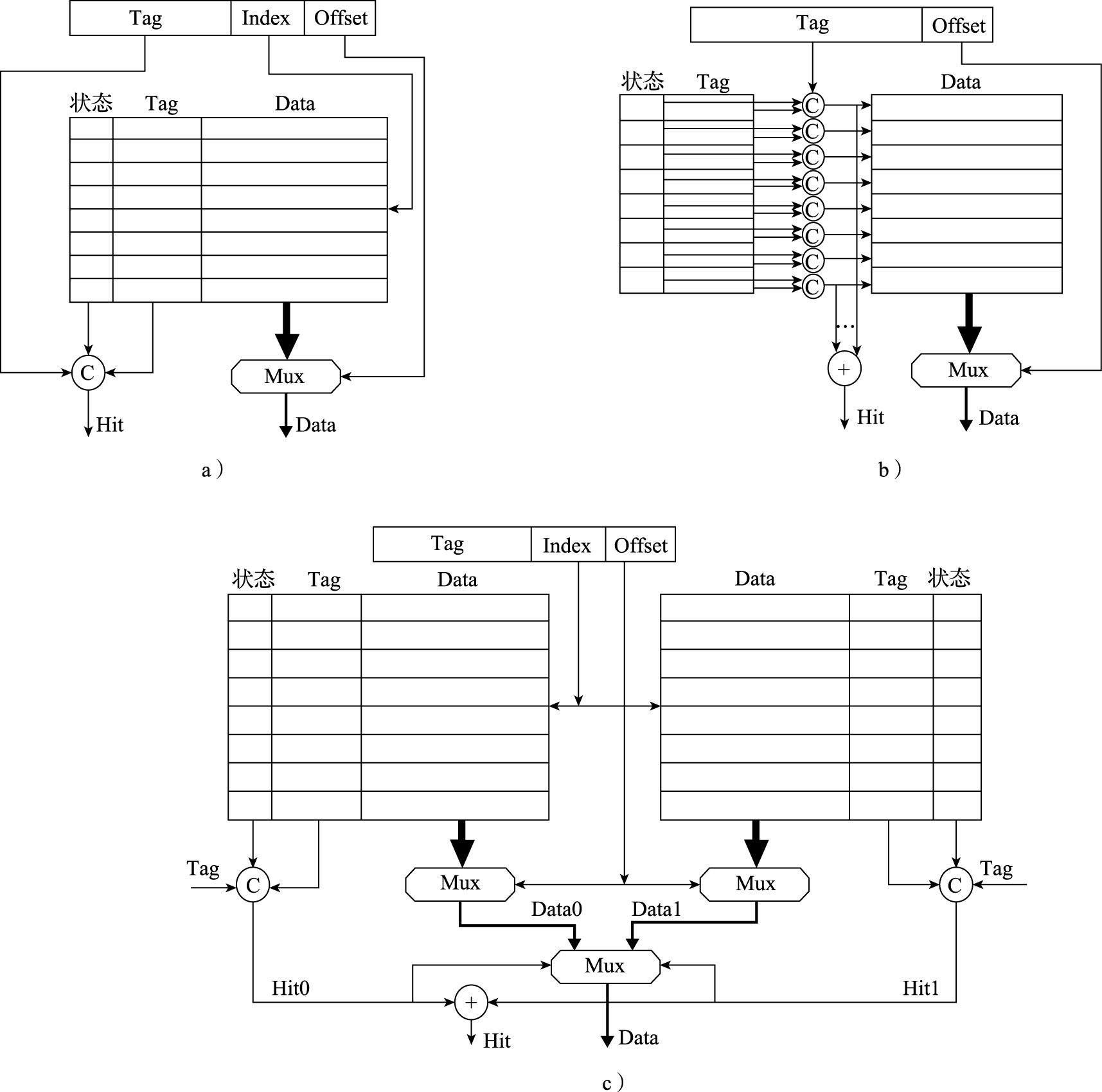
Cache索引方式
Cache的容量远小于内存,会涉及多个内存单元映射到同一个Cache单元的情况,具体怎么映射需要考虑。通常分为3种索引方式:直接相连、全相连和组相连。
Cache与下一层存储的数据关系
即写策略,分为写穿透和写回两种。存数指令需要修改下一层存储的值,如果将修改后的值暂时放在Cache中,当Cache替换回下一层存储时再写回,则称为写回Cache;如果每条存数指令都要立即更新下一层存储的值,则称为写穿透Cache。
Cache的替换策略
分为随机替换、LRU替换和FIFO替换。当发生Cache失效而需要取回想要的Cache行,此时如果Cache满了,则需要进行替换。进行Cache替换时,如果有多个Cache行可供替换,可以选择随机进行替换,也可以替换掉最先进入Cache的Cache行(FIFO替换),或者替换掉最近最少使用的Cache行(LRU替换)。
[1] 《计算机体系结构基础》胡伟武等


