问题的来源
参考之前的文章 –《缓存一致性》
写缓冲与写屏障
当引入写缓冲时,下面的程序会出现问题
|
|
在采用乱序执行的情况下,②(B的值写入StoreBuffer)->③(从StoreBuff中读到值为1)->④(本地缓存中a还是1)->assert失败
|
|
屏障的作用是前边的读写操作未完成的情况下,后面的读写操作不能发生,保证了a和b的写入缓存顺序
失效队列与读屏障
还是上面的程序,在引入失效队列后,会出现这样的情况,对a的修改,CPU1并没有立刻处理失效队列中请求(即没有立刻将CPU1中的a设置为失效)导致CPU1在读取a时,a还是0,最终assert失败
|
|
更加细粒度的读写屏障
分离的写屏障和读屏障的出现,是为了更加精细地控制 Store Buffer 和 Invalid Queue的顺序
- 读屏障不允许其前后的读操作越过屏障
- 写屏障不允许其前后的写操作越过屏障
|
|
总之, MESI的协议和StoreBuffer和invalidqueue的引入, 仍不能保证数据和顺序一致性
内存一致性模型
内存一致性模型(Memory Consistency Model,简称为内存模型)明确定义了不同核心对于共享内存操作需要遵循的顺序。读写操作之间共有四类先后顺序需要保证,即读操作与读操作的顺序、读操作与写操作的顺序、写操作与读操作的顺序、写操作与写操作的顺序 针对同一地址或者有依赖关系4的访存操作,处理器可以保证其顺序。因此在不同的内存模型中,主要讨论的是针对不同地址以及无依赖关系的访存操作之间的顺序
严格一致性模型
在严格一致性模型中,所有访存操作都是严格按照程序编写的顺序可见。此外,其要求所有核心对一个地址的任意读操作都能读到这个地址最近一次写的数据。因此,所有的线程看到的访存操作顺序都与其发生的时间顺序完全一致
顺序一致性模型
顺序一致性模型弱于严格一致性模型,其不要求操作按照其真实发生的时间顺序(即依据全局时钟定义的顺序)全局可见。顺序一致性模型提供了以下保证:首先,不同核心看到的访存操作顺序完全一致,这个顺序称为全局顺序;其次,在这个全局顺序中,每个核心自己的读写操作可见顺序必须与其程序顺序保持一致。不同于严格一致性模型,顺序一致性模型放松了对于时间顺序的要求,因此其中的读操作不一定能读到其他核上最新的修改。
TSO一致性模型
为了达到更好的性能,TSO一致性模型进一步弱化了访存一致性保证。在TSO 一致性模型中,其保证对不同地址且无依赖的读读、读写、写写操作之间的全局可见顺序,只有写读的全局可见顺序不能得到保证。TSO 一致性模型通过加入一个写缓冲区达成优化性能的目的,该写缓冲区能够保证写操作按照顺序全局可见,TSO 一致性模型(Total Store Ordering)也因此得名。
弱序一致性模型
弱序一致性模型(后文简称为弱序一致性模型)提供了较 TSO 更弱的一致性保证。在一个核心上,弱序一致性模型不保证任何不同地址且无依赖的访存操作之间的顺序,也即读读,读写,写读与写写操作之间都可以乱序全局可见。
内存屏障
是什么
几乎所有的处理器都至少支持一个粗粒度的屏障指令(通常称为 Fence,也叫全屏障),它保证了严格的有序性:==在 Fence 之前的所有读操作(load)和写操作(store)先于在Fence 之后的所有读操作(load)和写操作(store)执行完==。对于任何的处理器来说,这通常都是最耗时的指令之一(它的开销通常接近甚至超过原子操作指令)。大多数处理器还支持更细粒度的屏障指令。
不同于缓存一致性,内存模型对于上层软件不是透明的。在较弱的内存一致性模型中,为了保证特定访存操作的全局可见顺序,开发者必须手动添加硬件内存屏障(Barrier/Fence,简称内存屏障)。硬件内存屏障可以要求硬件保证访存操作之间的顺序。硬件往往提供多种不同的内存屏障指令来保证不同类型的访存操作的顺序。
不同的架构会根据自身使用的内存模型,提供不同的内存屏障指令。软件通过调用对应指令告诉硬件来保证特定类型访存操作之间的顺序
不同类型的屏障
LoadLoad Barrier (读读屏障)
|
|
保证了 Load1 先于 Load2 和后续所有的 load 指令加载数据。通常情况下,在执行预测读(speculative loads)或乱序处理(out-of-order processing)的处理器上需要显式的 LoadLoad Barrier。在始终保证读顺序(load ordering)的处理器上,这些屏障相当于无操作(no-ops)。
StoreStore Barrier(写写屏障)
|
|
保证了 Store1 的数据先于 Store2 及后续store 指令的数据对其他处理器可见(刷新到内存)。通常情况下,在不保证严格按照顺序从写缓冲区(store buffers)或者 缓存(caches)刷新到其他处理器或内存的处理器上,需要使用 StoreStore Barrier。
LoadStore Barrier(读写屏障)
|
|
保证了 Load1 的加载数据先于 Store2 及后续store 指令刷新数据到主内存。只有在乱序(out-of-order)处理器上,等待写指令(waiting store instructions)可以绕过读指令(loads)的情况下,才会需要使用LoadStore 屏障。
StoreLoad Barrier(写读屏障)
|
|
保证了 Store1 的数据对其他处理器可见(刷新数据到内存)先于 Load2 及后续的 load 指令加载数据。StoreLoad 屏障可以防止后续的读操作错误地使用了 Store1 写的数据,而不是使用来自另一个处理器的更近的对同一位置的写。因此只有需要将对同一个位置的写操作(stores)和随后的读操作(loads)分开时,才严格需要 StoreLoad 屏障。StoreLoad 屏障通常是开销最大的屏障,几乎所有的现代处理器都需要该屏障。之所以开销大,部分原因是它需要禁用绕过缓存(cache)从写缓冲区(Store Buffer)读取数据的机制。这可以通过让缓冲区完全刷新,外加暂停其他操作来实现,这就是 Fence 的效果。一般用 Fence 代替 StoreLoad Barrier ,所以事实上,执行 StoreLoad 指令同时也获得了其他三个屏障的效果,但是通过组合其他屏障通常不能获得与 StoreLoad Barrier 相同的效果。
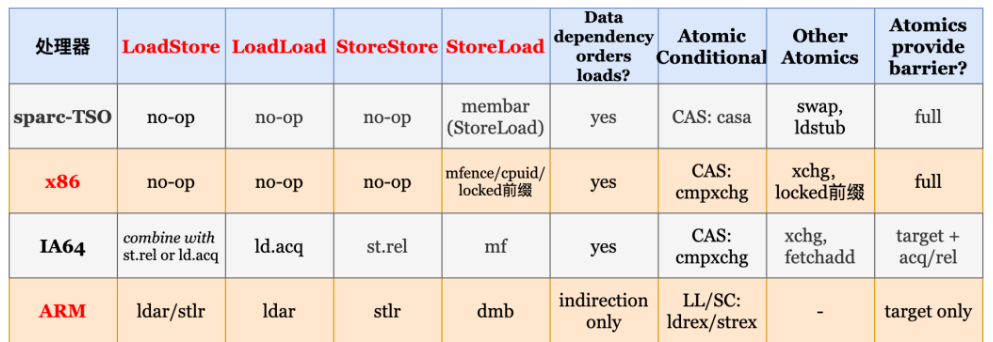
不同架构的内存模型与内存屏障设计
严格的内存模型对开发者更加友好,处理器的行为更容易被开发者理解。但其会造成处理器设计复杂,导致制造成本高、处理器能效低。而较弱的内存模型硬件设计简单,能够挖掘更多的并行潜能。但开发者必须更加小心地添加硬件内存屏障来保证程序的正确性。除此之外,对于同步需求大的并行应用程序,在弱序一致性模型下频繁使用内存屏障会带来显著的性能开销。
X86
Intel与AMD在X86架构下都使用了较强的TSO一致性模型 , 只有再写读操作会出现乱序, 因此在特性情况下添加内存屏障即可
TSO的特点决定了X86的屏障相对简单
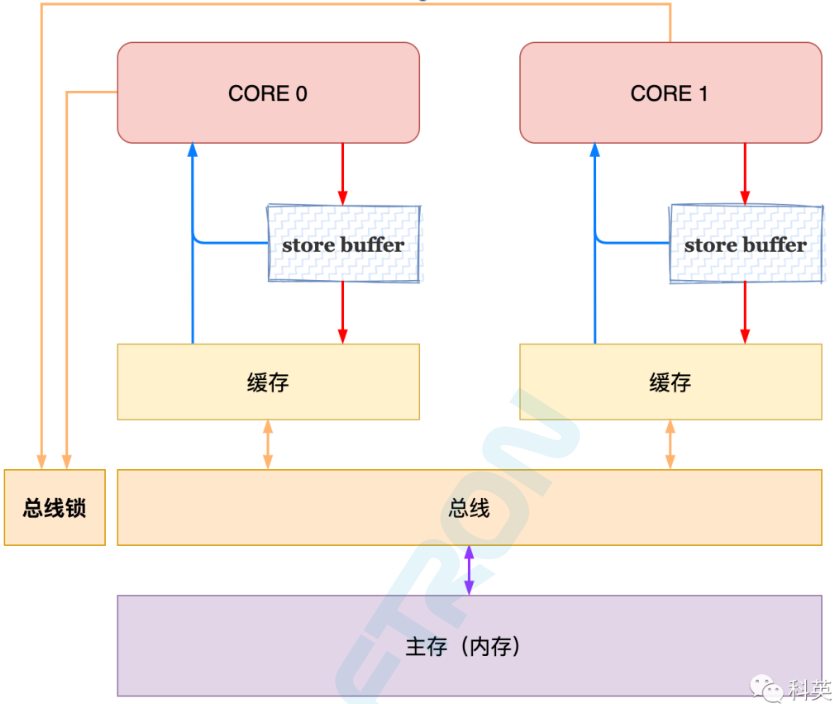
- StoreBuffer 被实现为FIFO队列,CPU务必优先读取本地StoreBuffer中的值,否则去缓存或内存中读取
- 没有引入无效队列
- MFENCE指令用于缓存清空本地StoreBuffer,并将数据刷到缓存和内存中
- CPU执行lock前缀的指令时,会去争抢全局锁,拿到锁后其他线程的读取操作会被阻塞,锁释放之前,会清空该线程本地的StoreBuffer,类似MFENCE
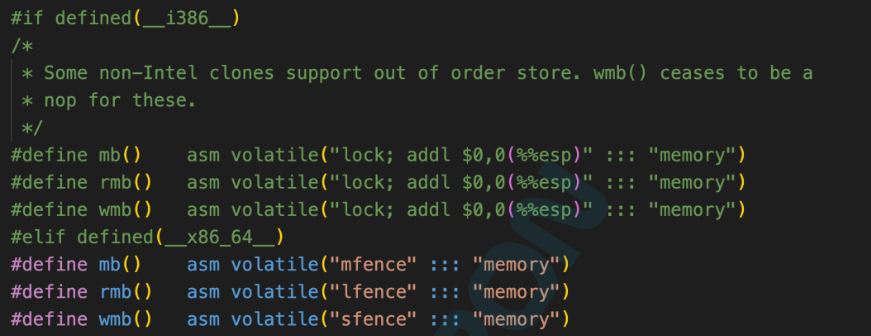
Linux中X86下的内存屏障定义
ARM :单向屏障
ARM使用了弱序一致性模型 , 必须注意所有的无依赖的访存之间是否需要添加内存屏障保证可见顺 , 但是在实际使用的场景中,只有涉及多核协作时, 才需要考虑访存操作的可见顺序
ARM采用了单向屏障。单向屏障 (half-way barrier) 也是一种内存屏障,但它不是以读写来区分的,而是像单行道一样,只允许单向通行,例如 ARM 中的 stlr 和 ldar 指令就是这样。 stlr 的全称是 store release register,包括 StoreStore barrier 和 LoadStorebarrier(场景少),通常使用 release 语义将寄存器的值写入内存; ldar 的全称是 load acquire register ,包括 LoadLoad barrier 和 LoadStorebarrier(对,你没看错,我没写错),通常使用 acquire 语义从内存中将值加载入寄存器;release 语义的内存屏障只不允许其前面的读写向后越过屏障,挡前不挡后;acquire 语义的内存屏障只不允许其后面的读写向前越过屏障,挡后不挡前; StoreLoad barrier 就只能使用 dmb(全屏障) 代替了。
总结
为了保证多核并行中,Cache和内存的数据一致性问题,可以使用写回和写直达策略。 但是在多核中,情况变得更加复杂了,就需要引入了缓存一致性协议,使得所有核心的私有缓存表现得和一个共享缓存的行为一致,缓存一致性协议主要处理两个核心问题,写传播和事务串行化,写传播就是每个CPU核心的写操作,要传播到其他核心,事务串行化使得所有的写入操作再所有CPU看来是一致的,但是无论是MSI,还是MESI协议都对CPU的性能产生了一定程度的负面作用,为此引入写缓冲区和失效队列,写缓存使得在写操作时,不需要等待其他核心的确认,直接放入到写缓冲区,等到其他核心确认后使其本地的Cache失效后,再写到Cache中,失效队列则是当其他核心发送RFO请求时,直接回复ACK,但是不需要立刻将缓存行失效,将请求放到失效队列,等有空再处理。 但是,写缓冲和失效队列的引入同样带来了新问题,在现代CPU的设计中经常使用指令乱序执行来提高CPU的运行效率,顺序和程序代码指令顺序不一致。在写操作执行之前就先执行了读操作。另一个原因是在同一个 CPU 中同一个数据存在不一致的情况 , 在 store buffer 中是最新的数据, 在 cache line 中是旧的数据。 内存屏障的提出就是解决这样的问题而来的,在程序适当的位置插入读写屏障,可以保证指令的执行顺序能够和程序员的预期一致。
[1] CPU缓存一致性:从理论到实战


