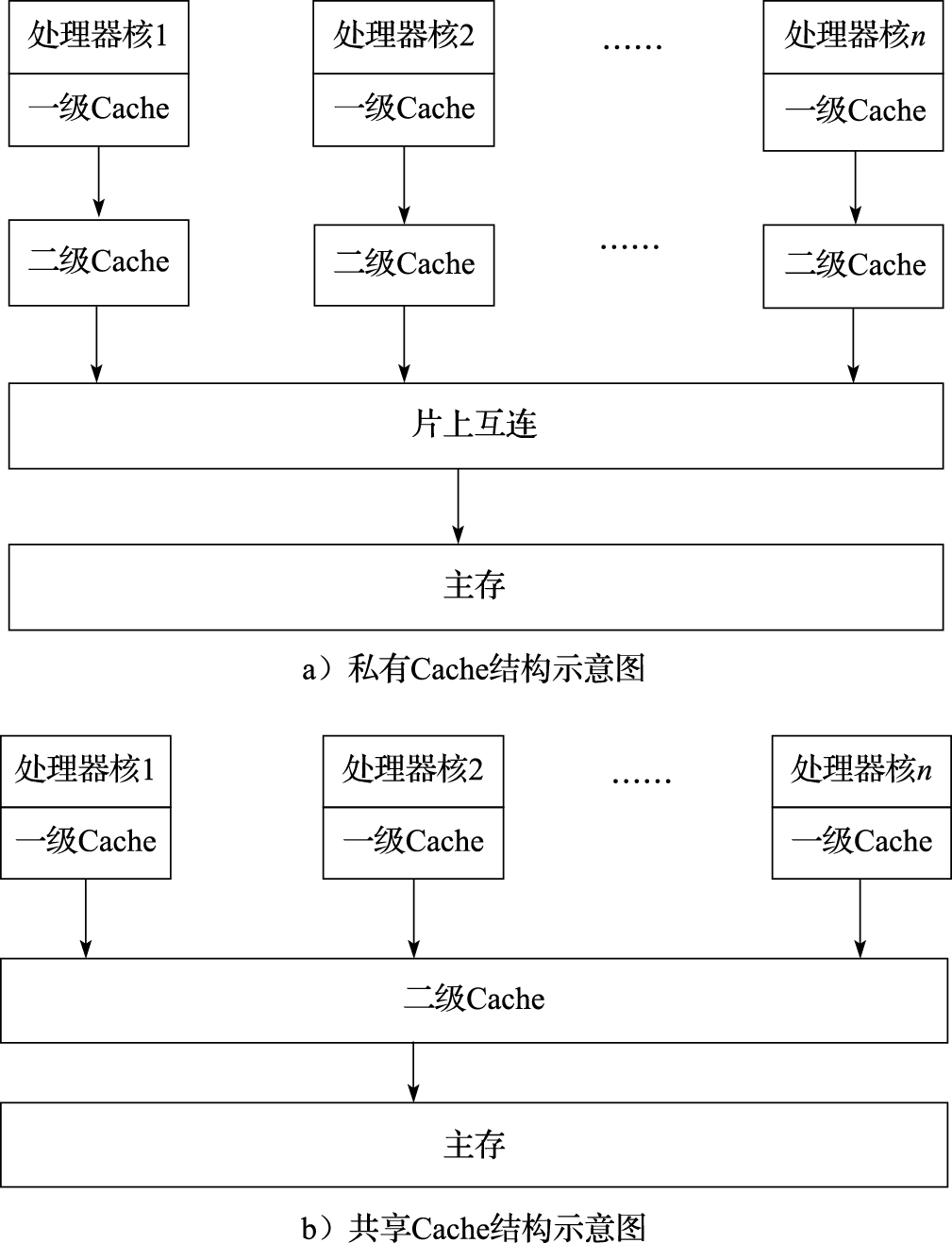
通用多核处理器的片上Cache结构
片上Cache的种类主要有:私有Cache、片上共享Cache、片间共享Cache 私有Cache结构具有较快的访问速度,但是具有较高的失效率。共享Cache结构的访问速度稍慢,但具有失效率低的优点。多处理器芯片间共享Cache结构的访问速度慢,且失效率高,因此并不常用。
多核主存结构(CC-NUMA为例)
目前 x86 NUMA 具体实现是 ccNUMA(Cache Coherent NUMA),在 NUMA 架构之上引入了缓存一致性协议,以确保不同节点之间的数据一致性,降低内核编写难度
NUMA(Non-Uniform Memory Access)非均匀内存访问架构。内存划分为多个块,每个 CPU 到不同内存块距离有远近之分,距离一个 CPU 近的内存块称为该 CPU的本地内存;距离相对远的内存块称为该 CPU 的非本地内存(也叫远端内存)。NUMA 内存架构把 CPU 和本地内存封装在一个 Node 节点里,并且将内存控制器芯片被集成到 CPU 内部,CPU 间通过 QPI(QuickPath Interconnect)链路相连。每个 CPU 访问本地内存非常快,没有了总线,相当于直接访问。但是有时例如本地内存空间不足等情况,一个 CPU 可以通过 QPI 访问另一个 CPU 所在 Node 节点内的本地内存,也就是一个 CPU 可以访问非本地内存。有的架构将PCI-E总线资源 (IOH)也集成到了 CPU 内部。
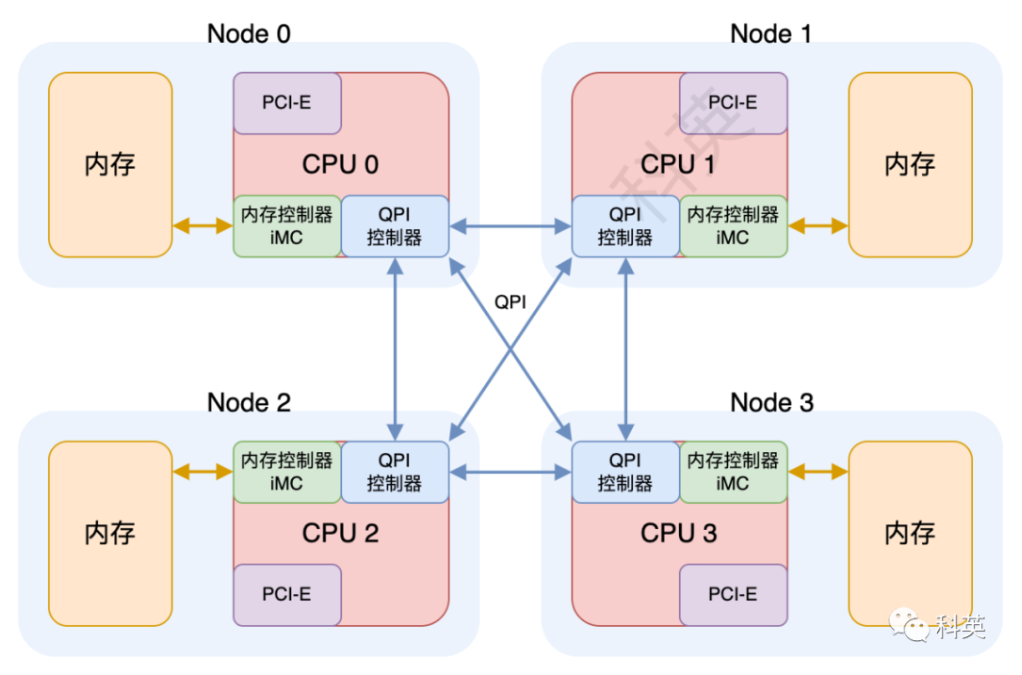
一个 Node 节点由一个物理 CPU、本地内存和本地 IO 资源组成。一个物理 CPU 由多个 CPU Core(核心)和一个 UnCore 部分组成。
- 每个 CPU Core 一般有 2 个 CPU Thread,也称逻辑 CPU Core(核心),top 命令里可见,每个逻辑核心独立运行,共享 Core 内部的逻辑运算单元(ALU)、浮点运算单元(FPU)、L1 和 L2 缓存;
- Uncore 集成了内存控制器 iMC(Integrated Memory Controller)、PCIe RootComplex、QPI 控制器、L3 缓存和 CBox(负责缓存一致性),及其它外设控制器
CPU 通过 Uncore 里的 iMC 直接访问本地内存,所以速度很快。但是访问非本地内存,则需要通过 QPI 链路到目标 Node 节点再通过 iMC 间接访问目标节点的本地内存,所以速度较慢。由此,应用和系统应尽量访问当前 CPU 的本地内存,来降低延时和提升性能
对于 PCI-E 等外设,通过 DMA 访问的内存,最好和外设在一个节点内,这样访问速度最快,要不然也和 CPU 一样,需要经过 QPI 链路访问远端内存。外设访问完 DMA 内存后,触发的硬中断和下半部的软中断会在同一个 CPU 上,那么这个 DMA 内存最好是该 CPU 的本地内存,这样速度才能快,也就是说要把同一个节点内外设的硬中断绑定到该节点内的 CPU 上。
[1]《操作系统:原理与设计》陈海波
[3] CPU缓存一致性:从理论到实战


